
How we eval the generator
The last post was a one-off: we hand-ran a prompt through the generator a few times and eyeballed whether it rebuilt a real app. Fun, but not a process. This is the process — how we actually measure whether vibes.diy's code generator produces good, working apps, and how we catch it when a change to the system prompt makes things worse.
Why eval at all
The generator is a moving target. Every time we edit the system prompt (prompts/pkg/system-prompt.md) — to teach it the Firefly access function, to change how it scaffolds, to add a new hook — we're changing the behavior of every app anyone generates. A wording tweak that helps sharing apps can quietly break timers. You cannot tell by reading the diff. You have to run real prompts through it and look at what comes out.
So we keep a catalog of prompts, generate apps from them on demand, score the results, and watch the averages move when we change the prompt. The unit of truth is a working app, not a clever-looking diff.
The shape of one eval
The main harness is the access-function eval. Every run is the same three moves:
shnpx vibes-diy@latest generate "<prompt>" --app-slug eval-<id> --verbose
npx vibes-diy@latest pull eval-<id> # download App.jsx + access.js
# read the files, score 1-5
Generate, pull, score. Do it for 46 prompts, some of them three times, and you have a picture of the generator's current quality.
Three prompt sets
The catalog (46 prompts) is split into three sets, and the split is the whole idea:
- Set A — as-is (20 prompts). Real home-page prompts run verbatim. This is the regression control: if a system-prompt change drops Set A's average, we broke something that used to work.
- Set B — enhanced (20 prompts). The same concepts as Set A, rewritten so the user describes sharing and privacy in plain language — "we each have our own," "only I can," "everyone sees" — with no platform vocabulary. This tests whether permission-shaped requests produce the right access model. Pairing each B with its A control lets us measure the delta cleanly.
- Set C — new capabilities (6 prompts). Business apps that were impossible before anonymous writes and channel isolation — contact forms, surveys, sign-up sheets. No baseline; these are net-new.
The Set C prompts read exactly like a non-technical person describing an idea. The contact-form-new prompt, in full:
Contact page for my landscaping business. Visitors fill out their name, phone number, and what they need done — they don't have to sign up or anything. I get a list of all the requests so I can call them back.
No mention of channels, anonymous access, or owner roles. The eval is whether the generator hears "they don't have to sign up" + "I get a list" and produces public-write, owner-only-read — without being told the words.
Set A vs Set B, in one pair
To make the A/B mechanic concrete, here's the goals pair run through the generator today. Same domain — goals with milestones — but Set B swaps in plain team-language.
Set A (goals-asis):
Goal tracker with milestones, a visual progress bar, and celebratory animations on completion.
Set B (goals-enh):
Team goals where the lead sets the milestones and everyone posts updates on their piece. Only the lead marks milestones complete.
The as-is prompt produces a private, single-user tracker — "QUEST TRACKER," every doc in the author's own channel. The enhanced prompt produces "TEAMTRACK," complete with a LEAD badge and a milestone form only the lead can use:
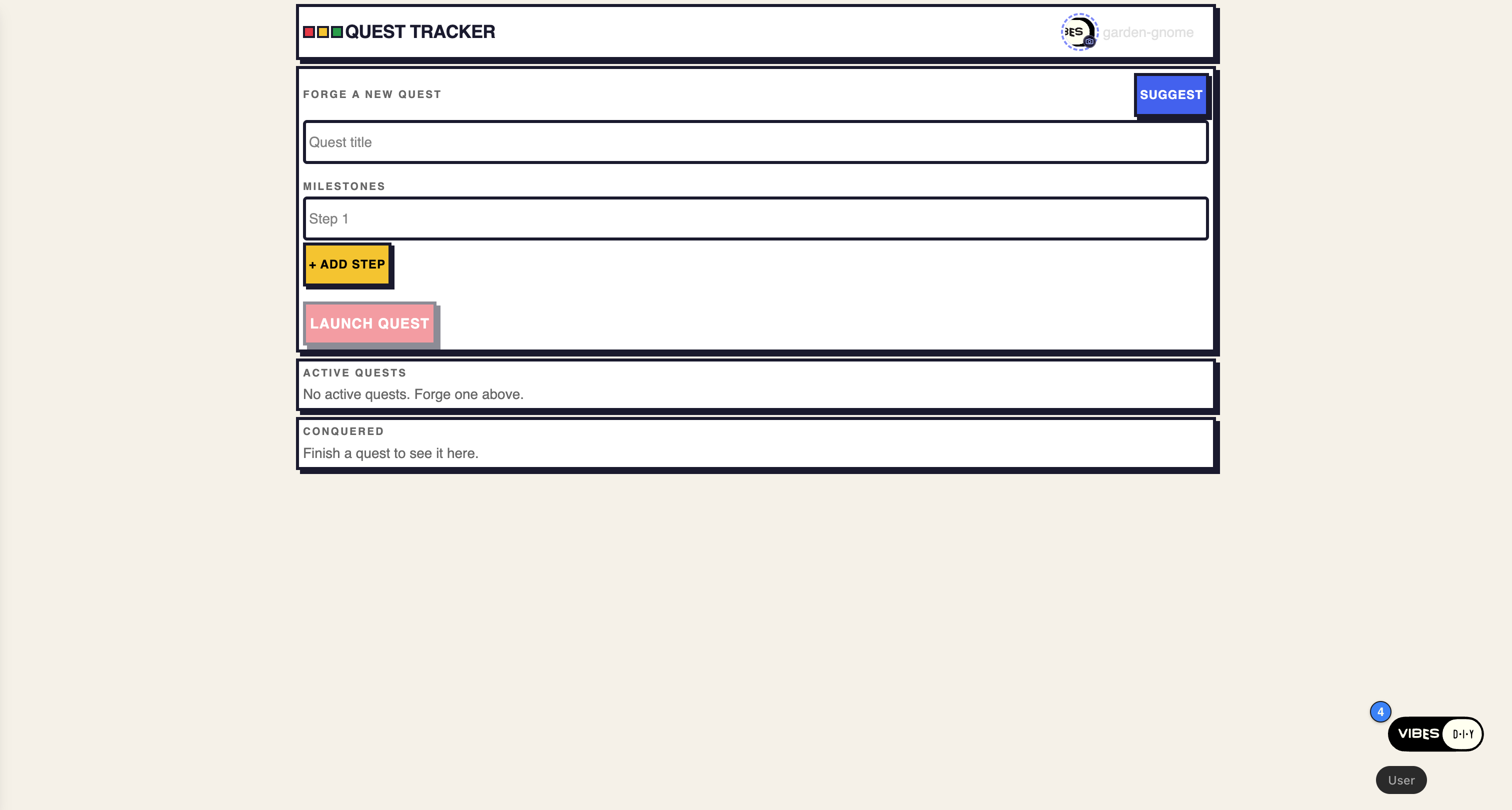
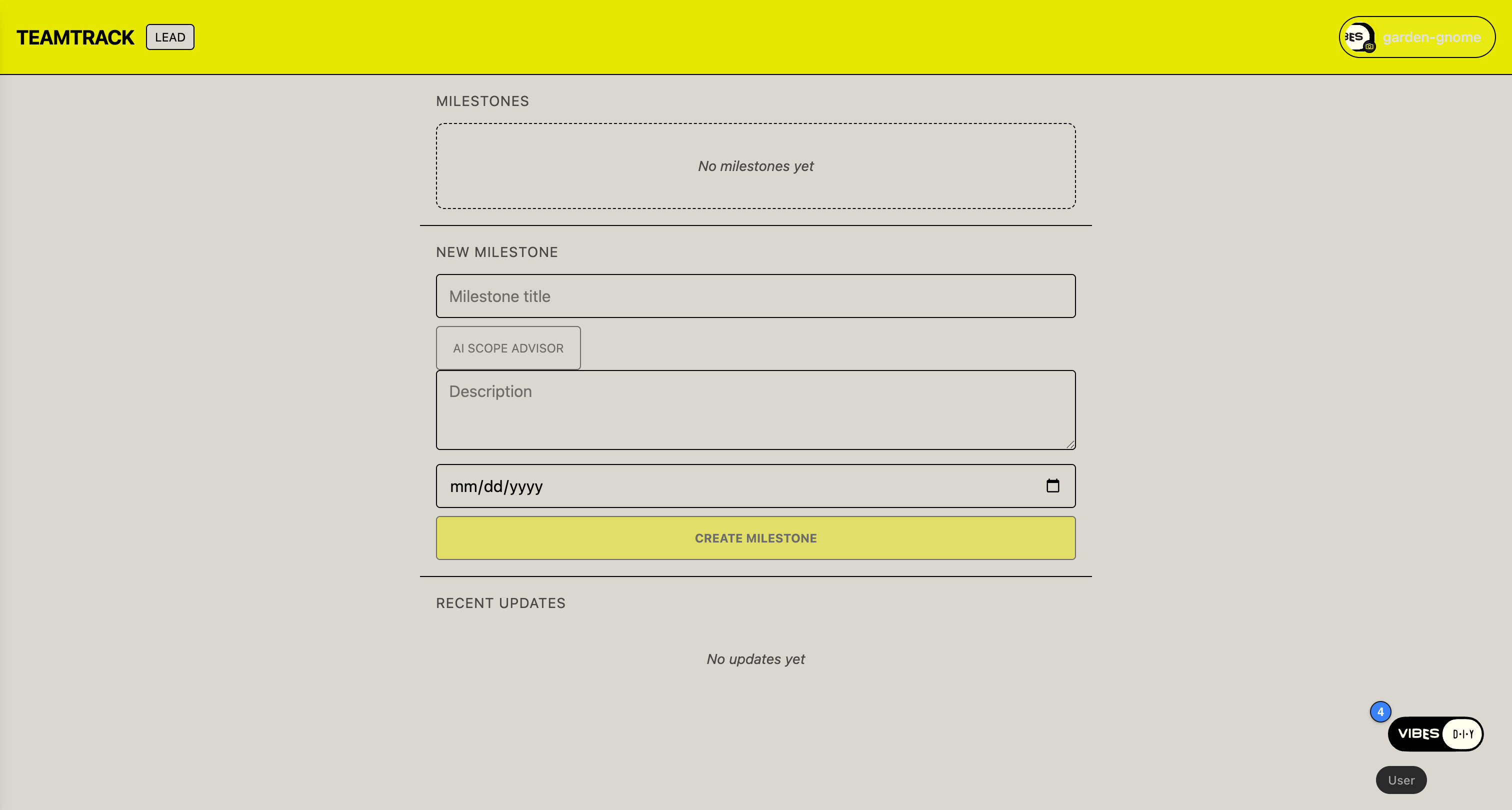
The difference shows up most sharply in the generated access.js. Before — one private channel per user, no roles:
Get posts like this in your inbox
One email field. Real updates. No algorithm required.
js// goals-asis: each user gets one private channel holding all their quests.
export default function (doc, oldDoc, user) {
if (!user) throw { forbidden: "sign in to track quests" }
if (doc.createdBy && doc.createdBy !== user.userHandle) throw { forbidden: "not author" }
const mine = `user:${user.userHandle}`
return { channels: [mine], grant: { users: { [user.userHandle]: [mine] } } }
}
After — two doc types with a lead/member split, the whole team on one shared board, milestone writes gated on isOwner:
js// goals-enh: "milestone" (owner-only writes) and "update" (any signed-in author).
export default function (doc, oldDoc, user) {
if (!user) throw { forbidden: "sign in" }
const channel = "team-board"
if (doc.type === "milestone") {
if (!user.isOwner) throw { forbidden: "lead only" } // "only the lead marks complete"
return { channels: [channel], grant: { public: [channel] } }
}
if (doc.type === "update") {
if (doc.authorHandle !== user.userHandle) throw { forbidden: "not author" }
return { channels: [channel], grant: { public: [channel] } }
}
throw { forbidden: "unknown document type" }
}
Two sentences of plain team-language — "the lead sets the milestones," "only the lead marks milestones complete" — flipped a private app into a role-gated team board, LEAD badge and all. That delta is exactly what the A/B pairing exists to measure: not "did it work," but "did the permission model bend to the words." (Live: goals-asis · goals-enh.)
Scoring: one number, plus signals
Each app gets a single 1–5 score for quality, not for whether it used any particular feature:
| Score | Meaning |
|---|---|
| 5 | Renders, all features work, UI coherent, workflow connects |
| 4 | Renders, most features work, minor gap |
| 3 | Renders but a key feature is broken or missing |
| 2 | Renders with errors or crashes on basic interaction |
| 1 | Fails to render or fundamentally broken |
Crucially, we don't score whether access.js was emitted. The access function is part of the platform now; if the model reaches for it, great, if not, fine — what matters is whether the app does what the prompt asked. We track access usage as informational signals alongside the score: did it emit access.js, use access.hasChannel() / access.hasRole(), gate management UI on isOwner, render authors with ViewerTag, use allowAnonymous. Those tell us how the access function is being adopted without letting "used the fancy feature" inflate a quality number.
The orchestration: a Workflow pipeline
Running 60 generations by hand would take a day and you'd lose track. So the eval is a Workflow that fans the work out across agents in three phases:
- Generate — one agent per run shells out
vibes-diy generate. - Pull + Score — as each generation finishes, an agent pulls the files, reads
App.jsx+access.js, and returns a structured score (validated against a JSON schema, so the model can't hand back malformed data). - Report — a final agent takes all the scores and computes per-set averages, triple-run variance, access-function adoption rates, and top/bottom findings.
It's a pipeline, not a barrier: a prompt that finishes generating gets pulled and scored immediately while others are still generating. The run list is derived from the catalog — each prompt once, plus the seven triple: true prompts three times — so the totals come from the data, never a hardcoded number.
The triple-runs are the variance probe. focus-timer-asis is a deliberate calibrator (should score 4–5 every time); a wide range there means the generator is flaky, not that the prompt is hard. Picks like contact-form-new and survey-new were chosen over gamier prompts because they isolate the access-function signal instead of bundling in render/game complexity.
The corpus lives in the repo
The generated apps don't evaporate. They're pulled into vibes/eval/ with a naming convention that encodes the set — -asis, -enh, -new, and -r1/-r2 for the repeat runs:
textvibes/eval/contact-form-new/ vibes/eval/contact-form-new-r1/ ...-r2/
vibes/eval/brain-dump-asis/ vibes/eval/brain-dump-enh/
vibes/eval/survey-new/ vibes/eval/meet-up-enh/ ...
Keeping the corpus checked in means a regression is a diff: when an app's score drops, you can read exactly what the generator produced this time versus last, instead of re-deriving it from a number.
What a run tells us
From the 2026-06-03 results (60 scored runs):
- Set averages: as-is 3.54, enhanced 3.33, new 3.08. Quality slips as the ask gets more permission-shaped and more net-new — exactly the gradient you'd want the eval to expose.
- Distribution is bimodal: ~42% score a perfect 5, but ~35% score 1–2. The generator either nails it or face-plants; the middle is thin. That's a more actionable finding than the 3.37 overall mean, and you only see it because every app is scored individually.
access.jsadoption: 100% across all three sets. The sharing language reliably triggers an access function;isOwnerandViewerTagare the dominant patterns. The unreliability is in app wiring, not in whether the permission model shows up.
Findings like "bimodal, and the failures cluster in net-new business apps" are what send us back to the system prompt with a specific thing to fix — then we re-run and watch the bottom mode shrink.
Two more harnesses for the edges
The access-function eval measures first-shot quality. Two sibling runbooks cover the parts that one prompt can't:
- Codegen-edit against local dev — drives the
codegen-editharness at a local Vite dev server so we can correlate eval outcomes with server-side recovery markers (apply-errors, recovery-orchestrator events). This is how we tell "the model wrote bad code" apart from "the apply/recovery loop dropped an edit." It comes with the gotchas you only learn the hard way: the dev server is ready when/apireturns 426, and you mustgrep -athe log because pnpm's TUI prefix hides worker JSON behind a wall of spaces. - Web → CLI edit fidelity — generate an app in the web chat, then send a follow-up through
vibes-diy editon the CLI, and verify the edit preserved the app (same database name, same features, only the files you asked for). Adb:inspectcross-check confirms the chat actually carried context to the LLM rather than starting fresh. This guards the promise that a CLI edit behaves like a web second prompt — they share the same server path, so they should be indistinguishable.
Both the local-dev and access-function evals also have a browser-driven mode: submit the prompt through the UI with Chrome MCP (using React's native setter so the state actually updates), wait 60–180s, then read the generated App.jsx + access.js against a review checklist — viewer gates writes, access.hasChannel() for permissions, isOwner for management UI, deterministic channel _ids, no stray emojis or callAI.
The human-in-the-loop version
Which brings it back to the Pickathon experiment. That was this exact loop, run by hand: pick a prompt, generate, pull, read the access.js, then load the deployed app in Chrome and check it does the thing. The harness just does it sixty times in parallel, scores each with a schema-validated agent, and rolls the result into one report — so when we change the system prompt, we know within a coffee break whether festival apps (and contact forms, and team boards) got better or worse.
Type a sentence. Get a working app.
The thing we measure is the thing you get to build.
Start building →